小电影的网站PYTHON爬虫,小电影的网站python爬虫动物
Python如何使用vscode+Python爬取豆瓣网电影排行榜
1、要使用VSCode与Python爬取豆瓣电影排行榜,首先确保安装了Python和VSCode,接着通过VSCode中文汉化包增强中文支持。选择IDE(集成开发环境)时,Python的编写与测试通常由IDE提供便利的环境。在遇到VSCode无法打开Python文件的错误时,可以通过将文件夹添加到工作区并使用Shift+Enter进行调试运行代码的解决办法。
2、首先,确保安装了requests库,这是数据获取的必备工具。我们的目标是猫眼验证中心,通过巧妙地分析分页逻辑,我们发现每页10部电影,使用`offset`参数进行递增式抓取,总共需10次请求,范围从0到90。
3、要运行Python代码,只需保存文件并在编辑器中右键选择“在终端中运行Python文件”或使用快捷键Ctrl+Shift+B运行。这允许你直接在编辑器内执行代码,无需切换到命令行。VSCode还支持Python代码检查器,如PyLint、flake8等,这些工具可帮助你检测代码质量问题,提高代码质量和可维护性。
4、首先,需要对项目的.vscode/launch.json文件进行配置,加入以下内容(注意,这一步只需在首个项目中执行,后续项目可以直接复制使用)。配置完成后,在VSCode的调试面板中会出现新的调试选项。此时,只需点击绿色三角图标启动调试,VSCode将暂停在程序的指定位置,等待远程连接。
用Python爬虫爬取爱奇艺上的VIP电影视频,是违法行为吗?
1、不管是用python还是其小电影的网站PYTHON爬虫他的语言来爬取电影资源小电影的网站PYTHON爬虫,都是不合法的。特别是VIP电影,都是有版权保护的,不适当的使用爬取的资源可能会给他人和自己带来很多麻烦。比如有些人下载了电影,然后再出售给其他人观看,这种性质更加严重,会被罚的很重。所以建议还是通过官方渠道观看就好了,不要私自爬取VIP电影。
2、爱奇艺以电影《哥斯拉大战金刚》为例,弹幕数据通过开发者工具抓包获得,视频每60秒更新一次数据包。评论数据在网页下方,通过抓包分析得到。知乎以热点话题《如何看待网传腾讯实习生向腾讯高层提出建议颁布拒绝陪酒相关条令?》为例,爬取回答内容。知乎的回答内容为动态加载,通过抓包分析得到。
3、python的用处很多,但最重要的是做数据分析。比如使用python做爬虫,爬取微博中关于某个事件的微博信息,通过聚类,回归分析人们的情感倾向,挖掘出微博中的热门词汇,挖掘用户的主要观点,监控事件趋势,走向等,还可以作为web网站的运行环境,提供web服务。
4、实战爬虫 实战项目包括爬取豆瓣短评、爱奇艺弹幕、王者农药皮肤、英雄联盟皮肤、QQ音乐歌曲、相亲软件评论等。数据分析与可视化 掌握Python在数据分析与可视化的应用,通过NumPy、Pandas、Seaborn、Pyecharts等库学习。实战分析与可视化 实际操作,如分析电影、绘制疫情图、可视化神器使用等,全面提升技能。
3分钟,10行代码教你写Python爬虫!
1、首先,导入必要的Python库:通过pip指令安装所需的库,具体如下:pip install -i pypi.tuna.tsinghua.edu.cn... --trusted-host pypi.tuna.tsinghua.edu.cn requests 并安装lxml库:pip install lxml pypi.douban.com/simple/ --trusted-host pypi.douban.com 第二步,选择爬虫目标网站。
2、利用python写爬虫程序的方法:先分析网站内容,红色部分即是网站文章内容div。随便打开一个div来看,可以看到,蓝色部分除了一个文章标题以外没有什么有用的信息,而注意红色部分我勾画出的地方,可以知道,它是指向文章的地址的超链接,那么爬虫只要捕捉到这个地址就可以了。
3、```python import requests url = https:// = requests.get(url)print(response.text)```以上代码中,首先导入了 requests 模块。然后定义了一个目标网站的 URL,并使用 requests.get() 方法向该 URL 发送 GET 请求,并将响应内容赋值给 response 变量。
一篇文章教会你利用Python网络爬虫获取Mikan动漫资源
1、本文将指导你如何利用Python编写网络爬虫,从新一代动漫下载站Mikan Project获取最新动漫资源。目标是通过Python库requests和lxml,配合fake_useragent,实现获取并保存种子链接。首先,项目的关键在于模拟浏览器行为,处理下一页请求。通过分析网页结构,观察到每增加一页,链接中会包含一个动态变量。
2、目标是获取动漫种子链接并保存至文档。涉及的库和网站 使用网站:Mikan Project 关键库:requests、lxml、fake_useragent 项目分析 需解决下一页网址请求问题,通过模拟点击实现自动请求多页。反爬措施 设置常规HTTP请求头,使用随机UserAgent进行访问。
爬无止境:用Python爬虫省下去电影院的钱,下载VIP电影,我刑啦
为了确保高效下载小电影的网站PYTHON爬虫,首先需搭建一个开发环境。同时,引入必要小电影的网站PYTHON爬虫的第三方库,进一步增强功能。此外,我精心准备了一段视频教程,专为初学者设计,详细讲解了Python下载视频的全过程,确保每个步骤清晰明了。
至此,电影爬取成功。程序可优化之处不少,如线程和数据持久化。初学者可通过此项目练习,分析网站规则,修改解析html的代码,爬取其他网站。
在实际的爬取过程中,首先明确目标,即要抓取豆瓣电影排行榜的数据。通过设置合适的请求头`headers`,如添加`User-Agent`来伪装访问请求,以避免触发网站的反爬虫机制。使用`requests.get(url=url, headers=headers)`获取数据后,利用`etree.HTML()`将获取的文本转换为HTML格式。
爬取时间:2020/11/25 系统环境:Windows 10 所用工具:Jupyter Notebook\Python 0 涉及的库:requests\lxml\pandas\matplotlib\numpy 蛋肥想法: 先将电影名称、原名、评分、评价人数、分类信息从网站上爬取下来。
网络上有许多用 Python 爬取网页内容的教程,但一般需要写代码,对初学者来说门槛较高。其实,对于大部分场景,使用 Web Scraper 插件就能快速获取所需内容,无需下载额外软件,也不需具备代码知识。
python爬虫-11-用python爬取视频网站电影天堂中每一个视频的详情,看电...
1、整体定位:爬取页面内容。示例页面中小电影的网站PYTHON爬虫,电影信息散落其中。定位到具体电影时小电影的网站PYTHON爬虫,需要关注页面结构。范围定位:确定爬取范围小电影的网站PYTHON爬虫,即页面中小电影的网站PYTHON爬虫的电影列表,获取列表中的每一个电影链接。大致定位:聚焦于每个电影详情页面中的关键信息,定位到包含主演、国家、简介等内容的区域。
2、确定页面与内容定位: - 通过浏览器的开发者工具,找到目标信息所在的HTML代码区块。确保能识别出包含所需数据的元素。 确定XPath路径: - 确定每个元素的XPath路径,以便在Python代码中精确定位。 代码实现: - 使用Python库如BeautifulSoup和requests获取网页HTML内容。
3、首先,通过使用Fiddler抓包,我找到了一个随机电影链接的post请求。通过分析,我了解到提交post请求的url包含了要下载的电影的url,只是因为url编码为了ASCII码,所以需要使用urllib进行解析。vkey是动态变化的,隐藏在post请求前的get请求返回页面中。
4、只需通过简单的代码操作,便能实现视频的快速下载,无论你渴望观看何种电影,Python都能助你一臂之力。为了确保高效下载,首先需搭建一个开发环境。同时,引入必要的第三方库,进一步增强功能。此外,我精心准备了一段视频教程,专为初学者设计,详细讲解了Python下载视频的全过程,确保每个步骤清晰明了。
5、要使用VSCode与Python爬取豆瓣电影排行榜,首先确保安装了Python和VSCode,接着通过VSCode中文汉化包增强中文支持。选择IDE(集成开发环境)时,Python的编写与测试通常由IDE提供便利的环境。在遇到VSCode无法打开Python文件的错误时,可以通过将文件夹添加到工作区并使用Shift+Enter进行调试运行代码的解决办法。
6、打开要抓取的网页,如豆瓣 Top250(movie.douban.com/top250),使用快捷键(在 Windows 上是 Ctrl+Shift+I,而在 Mac 上是 Option+Command+i)进入开发者模式查看网页的 HTML 结构。点击 Web Scraper 图标,进入爬虫页面。接下来,我们需要根据网页结构创建爬虫。
相关文章
-

草文化传媒有限公司招聘:糖心深夜释放自己vlog旧版本链接-第十批集采降价凶猛,“地板价”药品质量如何保障
-
小电影的网站PYTHON爬虫,小电影的网站python爬虫动物
-
代为签约、“整晕”记者,央视曝光“先享后付”背后的层层暴利
-
糖心app下载安卓版:糖心官方网站免费-西安比亚迪年产量首破百万,目前西安工厂日产4000至4400辆
-
糖心vlog无限观看次数怎么刷:水蜜桃91pony-人大中国古代文学教研室原主任姚梅屏逝世,曾参与多部辞典编写
-
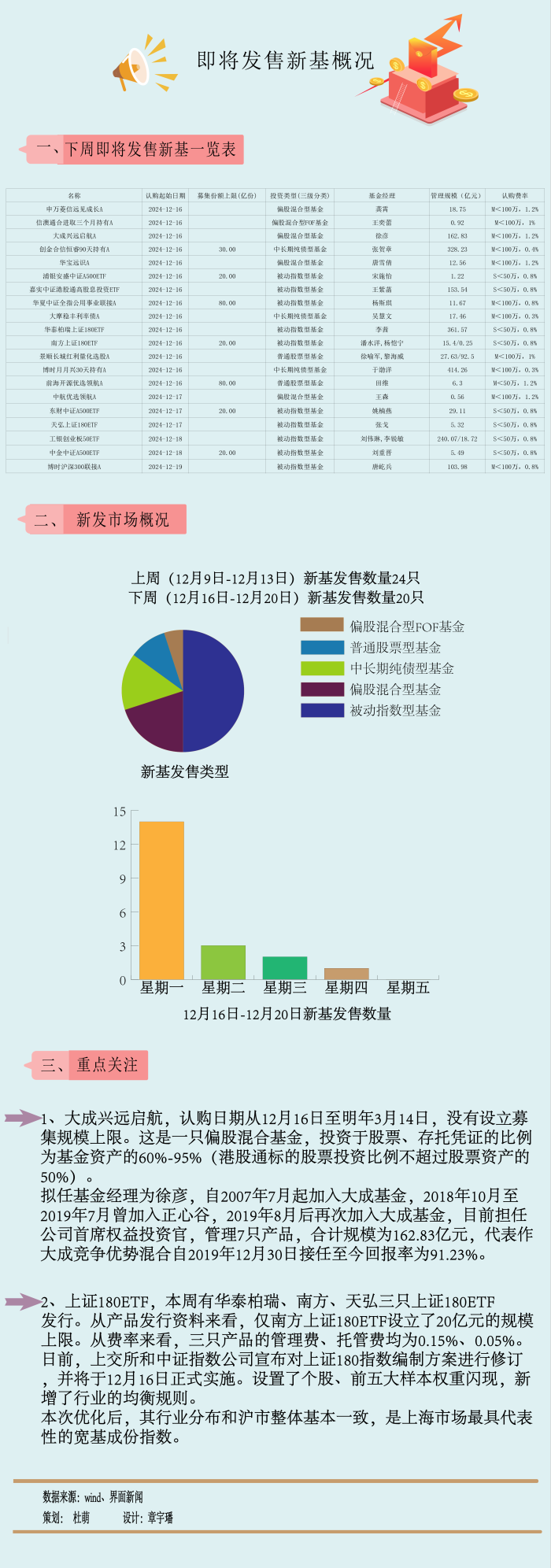
糖心app短视频下载:黑料正能量index.php2024-【一周新基】“升级版”上证180ETF陆续上新,指基仍在唱主角
-
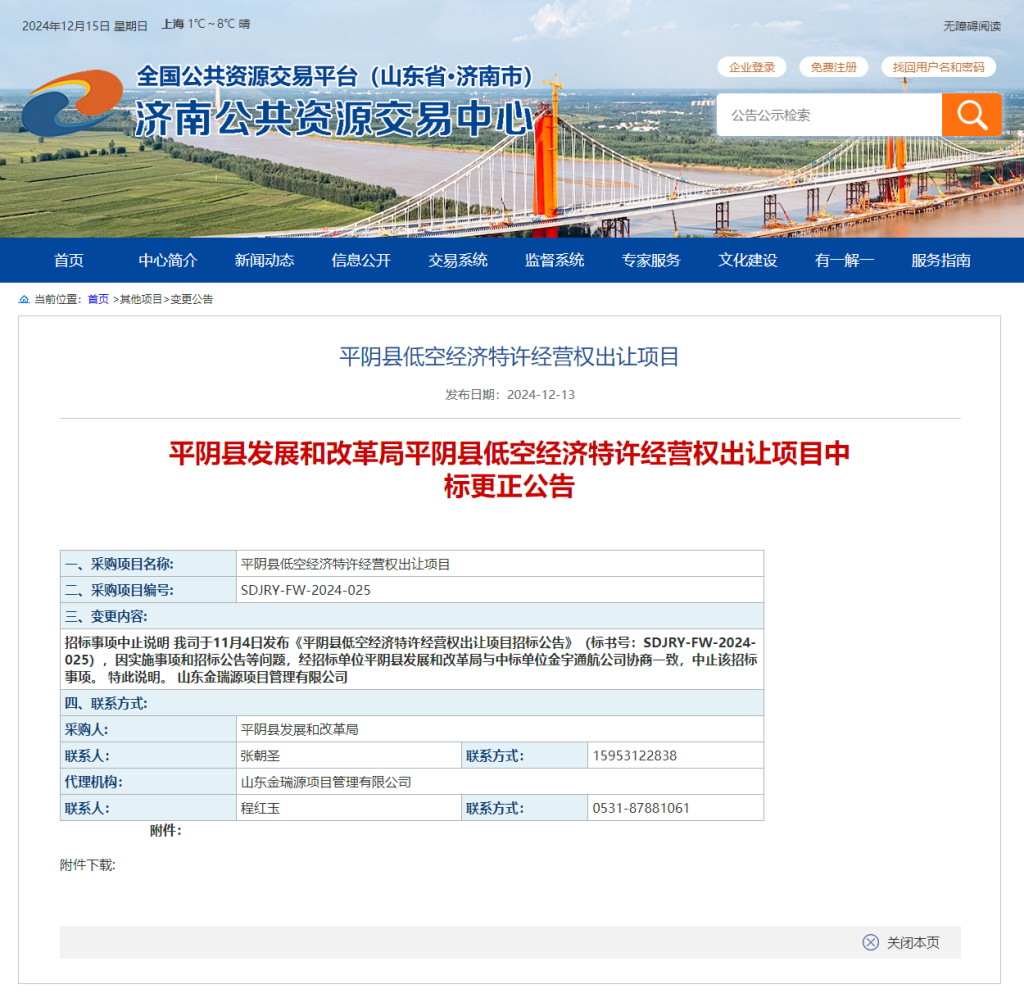
糖心live全集免费观看:糖心vlog下载污api-平阴县低空经济特许经营权出让项目中止招标
-
梵克雅宝高珠受《金银岛》启发,梅西卡复古演绎“午夜的太阳”|当周珠宝